Hi all, I am Coleman Krawczyk. My role for the Anti-Slavery Manuscripts project has been building the data aggregation code. In other words, I write the code that combines each of the volunteers’ transcriptions into one consensus transcription. This is also the code that draws the underline markings on the pages to indicate what lines of text are finished (grey lines), or what lines other volunteers have worked on (red lines in the collaborative workflow). In this blog post, I want to walk through how this aggregation process works and (just as importantly) point out the cases where it does not.
Clustering
Before jumping in too deeply into the process, I just want to give a brief introduction on how data clustering works. The goal of this process is to identify areas of “high density” in the data. For the Anti-Slavery Manuscripts project, these “high density” areas refer to places where volunteers have marked lines on an image. When multiple volunteers underline the same line of text on an image, the code groups those lines together to make one single line. To find the “high density” areas you need to define two different parameters: the minimum density for a cluster, and the minimum number of points that should be considered a cluster.
Cluster by angle
The first step of the process is to cluster the slope of the drawn lines of text. This separates out text written horizontally from text written at odd angles (e.g. cross writing, vertical writing in the margins, etc…).
Column detection
Once grouped by angle, the code looks for any columns in the text. This is a difficult problem to solve, so we only used a simple definition of a column, “no drawn lines cross the gutter between columns.” This works well in some cases, but it only takes one stray transcription to break it. In the example below (a memo of English correspondence from Samuel May), the space between the written text on the left and right sides of the page would refer to the “gutter. “ The green lines are annotated correctly, while the red line at the top is drawn through the gutter.

Cluster by line
Next clustering is done in the vertical direction (after rotation by the detected angle). This finds all the unique lines of text on the page.
Cluster endpoints
The final round of clustering is done in the horizontal direction in order to detect the start and end points for each line of text.
The balancing act
For each of the clustering steps above we have control over those two parameters of “density” and “min size”. For the collaborative workflow, we want to make sure all previous transcriptions are shown for a page so this means our “min size” will be 1 for all of the clustering; that is, once one person has annotated and transcribed a line, the code will keep that annotation (underline) and transcription to show to the next volunteer. This leaves the density parameter as our only way to control how the clustering works, and this one value needs to be applied to all the letters being transcribed. Because every subject is different, there are cases where the aggregation will break. Below, you’ll find some examples where this has happened — you may recognize some of these letters from the project Talk boards.
When the min density is set too high
In this case, lines that should be clustered together are not.

This example clearly shows many lines of text that are double underlined. In this case, the lines are just different enough that the code does not register them as the same line.
When the min density is set too low
On the flip side of that problem is the case where multiple lines are being viewed as a single line. This results in in transcriptions from different lines of text being included in the same dropdown menu (shown below).
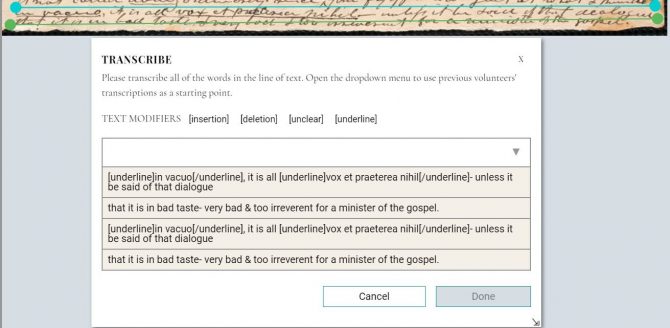
In this case, we can see that the two lines of text just above the green annotation are being treated as the same line.
Columns are not detected
Our column detection code assumes that a column will extend the full height of the page. Unfortunately, this assumption is not always true. In the image below, we can see the code creates one long horizontal line, rather than allowing the text to remain separated into columns. In these cases, the dropdown menu can become very confusing.

Notice how the code was able to detect the shorter line in the upper right corner without issue (in grey), but failed to find the shorter line on the left side. This is because the line on the right has no other text at the same vertical position, but the text on the left does.
How to tell when a line is finished?
The last topic I want to talk about is how the code decides when a line of text is finished, and should be greyed-out. After a line is detected with the clustering code, a text alignment code is run to find the best “consensus” text.
Consensus score
Let’s look at an example line of text:

The following transcriptions were submitted
- & tell who I know- [deletion]I can not think[/deletion]
- & tell what I know - [deletion]I cannot think[/deletion]
- & tell what I know - [deletion]I cannot think[/deletion]
- & tell what I know - [deletion]I cannot think[/deletion]
Notice there are some subtle differences in the spacing used around the “-” and for the word “cannot”. The code first splits the text on whitespace, then aligns the text word by word. In this case, it produces:
| & | tell | who | I | know- | [deletion]I | can | not | think[/deletion] | |
| & | tell | what | I | know | - | [deletion]I | cannot | think[/deletion] | |
| & | tell | what | I | know | - | [deletion]I | cannot | think[/deletion] | |
| & | tell | what | I | know | - | [deletion]I | cannot | think[/deletion] | |
| 4 | 4 | 3 | 4 | 3 | 3 | 4 | 3 | 1 | 4 |
The final consensus line of text is constructed by taking the word from each column with the most votes (shown in bold): “& tell what I know - [deletion]I cannot not think[/deletion]”.
The table above also lists the number of votes the most common word from each column received. By adding these up and dividing by the number of words, we can form the “consensus score”, or in other words “the average number of people who agreed for this line of text.” In this case, we get 33/10 = 3.3.
We mark a line as finished when the consensus score reaches three or higher, or if five volunteers have transcribed the line. The second condition is in place to make sure very unclear lines of text, or instances where the cluster went wrong (as shown above), don’t prevent a subject from being finished. This condition is also a good way to flag to the BPL team that a difficult line of text might benefit from expert review.
Whitespace and tags
As one last example, I want to show what happens when whitespace is not inserted after custom tags. Here is the example line of text:
![]()
The transcriptions:
- to let [deletion]Sar[/deletion]Angelinea give [underline]all[/underline]the
- to let [deletion]I am[/deletion] Angelina give all the
- to let [deletion]Sar[/deletion]Angelinea give [underline]all[/underline]the
- to let [deletion]Sar[/deletion]Angelinea give [underline]all[/underline]the
- to let [deletion]Sar[/deletion]Angelina give [underline]all[/underline]the
| to | let | [deletion]Sar[/deletion]Angelinea | give | [underline]all[/underline]the | |||
| to | let | am[/deletion] | Angelina | give | all | the | |
| to | let | [deletion]Sar[/deletion]Angelinea | give | [underline]all[/underline]the | |||
| to | let | [deletion]Sar[/deletion]Angelinea | give | [underline]all[/underline]the | |||
| to | let | [deletion]Sar[/deletion]Angelina | give | [underline]all[/underline]the | |||
| 5 | 5 | 3 | 1 | 1 | 5 | 4 | 1 |
Consensus score: 3.125
Consensus line: “to let [deletion]Sar[/deletion]Angelinea am[/deletion] Angelina give [underline]all[/underline]the the”
In this case, we can see that the word alignment has not given very good results. The main reason for this is the lack of space between the closing metadata tags (e.g. [/deletion]) and the word that follows it.
If those spaces were inserted correctly, the alignment would have been:
| to | let | [deletion]Sar[/deletion] | Angelinea | give | [underline]all[/underline] | the | |
| to | let | [deletion]I | am[/deletion] | Angelina | give | all | the |
| to | let | [deletion]Sar[/deletion] | Angelinea | give | [underline]all[/underline] | the | |
| to | let | [deletion]Sar[/deletion] | Angelinea | give | [underline]all[/underline] | the | |
| to | let | [deletion]Sar[/deletion] | Angelina | give | [underline]all[/underline] | the | |
| 5 | 5 | 4 | 3 | 2 | 5 | 4 | 5 |
Consensus score: 4.125
Consensus line: “to let [deletion]Sar[/deletion] Angelinea Angelina give [underline]all[/underline] the”
Even with correct spacing, the transcription still isn’t perfect, but it is much cleaner than the first case.
Further applications for project data
Now that the first round of collaborative transcription is complete, we’re looking at the raw and aggregate transcriptions. We want to see whether we need to tweak any of the clustering settings described above, to produce cleaner data. Once that process is done, we’ll share another blog post to give you an update on the process.
If you have any questions about the data aggregation process, please feel free to post on the project Talk boards.

Add a comment to: Aggregating Annotations in the Anti-Slavery Manuscripts Project