This is a guest post written by Samantha Blickhan, IMLS Postdoctoral Fellow at the Adler Planetarium in Chicago, and the Humanities Lead for Zooniverse.
Dear volunteers and friends of anti-slavery manuscripts (ASM),
As of August 12, 2020, the volunteer transcription phase of Anti-Slavery Manuscripts (ASM) is officially complete! To celebrate and acknowledge this monumental effort, I wanted to share some statistics for the project as a whole. I also want to share information about the outcomes of the project, including what will happen next to prepare the project data for inclusion in the Boston Public Library (BPL) catalog.
Project Statistics: Overview
Between January 23, 2018 and August 12, 2020, 26,059 people participated in the project (14,115 of whom are registered Zooniverse volunteers). This team of volunteers transcribed a total of 12,247 letters from the BPL’s Anti-Slavery Collection. This includes:
- Annotating 1,797,061 lines of text (and agreeing with one another’s previous transcriptions 716,931 times!)
- Completing 78,058 transcriptions — remember, our transcription method is based on a consensus model, so each letter is essentially transcribed in triplicate!
Beyond the transcription task, you also spent a significant amount of time communicating with one another, and with the project team. Over the project period, volunteers and research team members posted a total of 16,971 comments across 8,121 talk threads.
Our cohort is international! The top ten countries from which volunteers participated are:
- United States
- United Kingdom
- Canada
- France
- Australia
- Germany
- Spain
- Netherlands
- Italy
- India
Project Results: ASM Data & Zooniverse Transcription Tools
So what are the outputs of this project? For example, what will we do with this MASSIVE amount of data that you’ve produced? Great question. There are a few different use cases for this data: making it publicly available via the BPL catalog, and using it to train a machine learning model. Additionally, the collaborative transcription tools will be included as part of the Project Builder toolkit. This means anyone who builds a Zooniverse text transcription project will have the option to use this transcription method.
1.Review & public release of transcription data
First and foremost, we need to review the data and upload it into the BPL’s statewide digital repository system at digitalcommonwealth.org. Here, the images and text of the collection will be freely available for users to download, search, and research.
The way we’re doing this is through use of a brand-new, not-even-publicly-launched-yet Zooniverse tool called ALICE. ALICE stands for Aggregate Line Inspector and Collaborative Editor. ALICE is a tool for working collaboratively to view and edit the output of text transcription projects on Zooniverse. It was built with support from a Digital Humanities Advancement Grant from the National Endowment for the Humanities.
Registered Zooniverse users (who have been added to a project as team members in the Collaborators tab of the Project Builder) are able to use their Zooniverse credentials to log into ALICE from their browser. There, they can view a list of transcribed documents. For each document, reviewers can see an automatically-generated aggregate transcription for each line of text on the page:
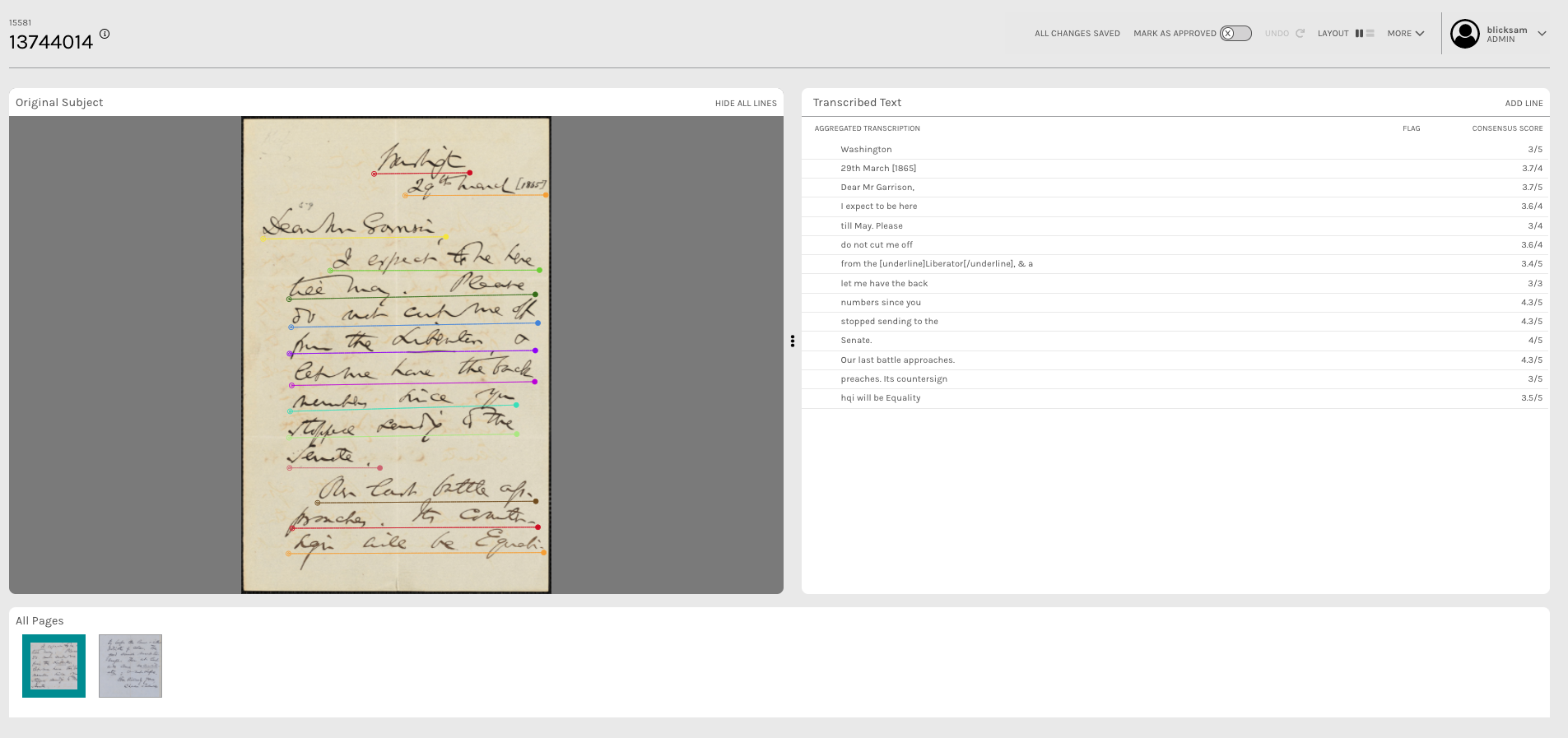
Clicking on an aggregate transcription will also produce a list of all transcriptions submitted for that particular line:
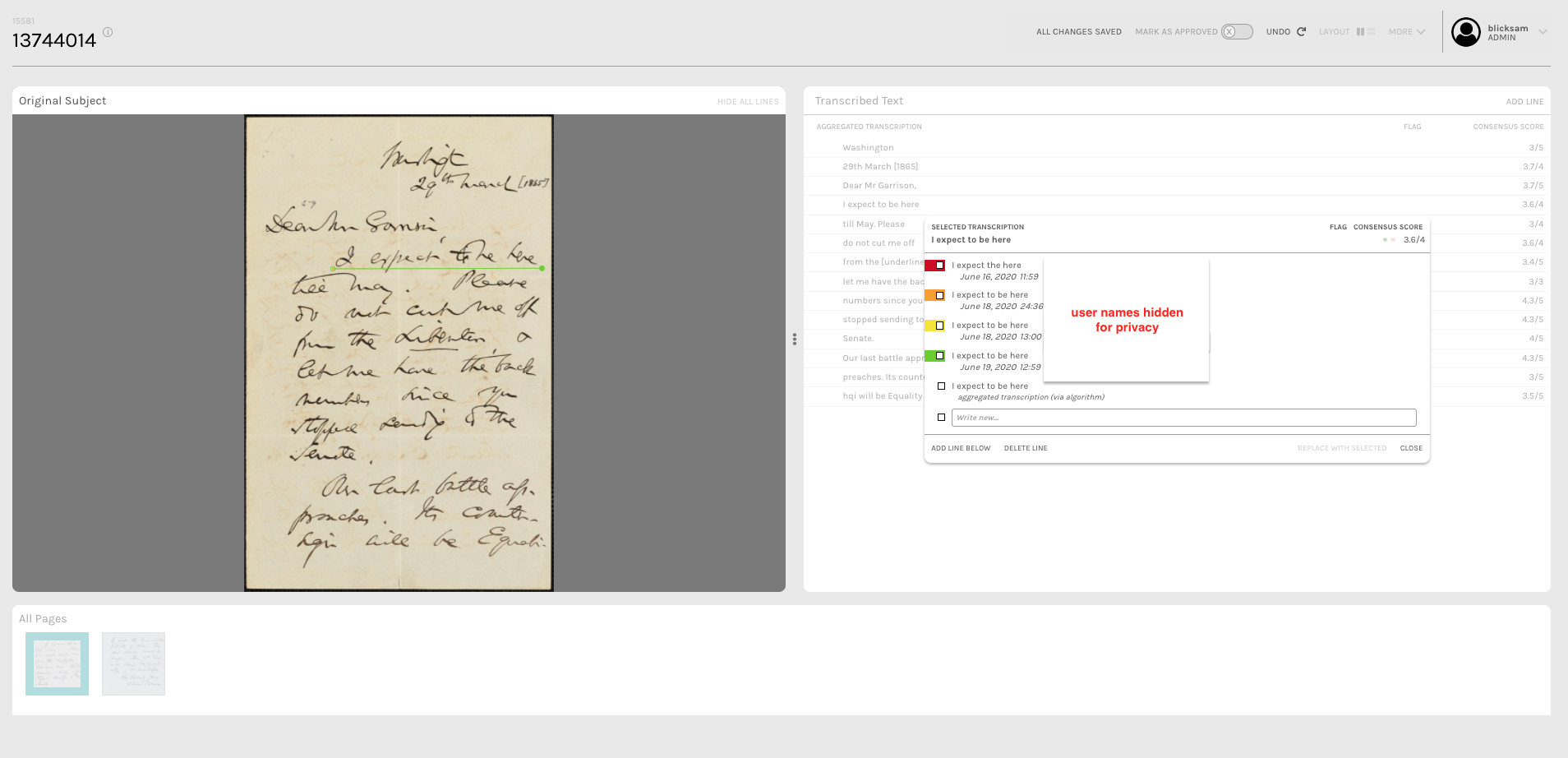
There are a number of additional editorial features built into the tool, including the ability to replace an aggregate line with an individual’s transcription, rearrange line order, and re-aggregate individual subjects. When a document is marked as ‘Approved’, teams can download a data export containing:
- Line by line transcription and metadata (.csv)
- Text-only file (.txt)
- Raw, unparsed transcription data (.json)
We’re pretty excited about the public launch of ALICE, and will be blogging more about it as we get closer to the release — watch blog.zooniverse.org for forthcoming information.
2. Using ASM data to produce automated methods
The second use case for the ASM transcription data is as a training dataset. Starting in December 2020, we’ll be starting a research project with colleagues at the University of Minnesota.
The project will explore the use of machine learning as a resource for online crowdsourced transcription projects. This project will be supported by a Digital Extension Grant from the American Council of Learned Societies. Read more about this project on the Zooniverse blog.
3. Generalizing ASM transcription tools for widespread use
Early on during the ASM project, we ran an A/B experiment to test the effect of independent vs. collaborative transcription methods on the resulting data quality. I blogged about that process in September of 2018 here. That test resulted in a peer-reviewed paper, which is publicly accessible here. To summarize, we found that collaborative transcription resulted in significantly higher quality results. This was measured by comparing the outputs of both efforts to gold standard transcription data. Crucially, though, the paper also acknowledged that transcription quality is not the only determining factor of crowdsourcing projects. New tools are meaningless if they result in a negative experience for volunteers.
To that end, we made sure to incorporate the feedback that ASM volunteers provided on the talk boards and via email. This isn’t an exhaustive list, but the forthcoming tool will include the following volunteer-requested updates to the ASM transcription tool:
- Ability to read greyed-out text
- Ability to adjust the placement of previously-drawn lines
- Fixed some issues with the placement of the transcription box
- Larger text to show which lines feature previous annotations
I and the rest of the Zooniverse team want to offer our heartfelt thanks for all the feedback and bug reports you’ve provided during this project. ASM was the very first run of these new tools, and we’re incredibly grateful for your patience and willingness to work with us. As with ALICE, keep an eye on blog.zooniverse.org for updates about the full launch of these tools in the Project Builder!
What’s next?
We’ll keep you updated here and on the talk boards (and via email, if you’re subscribed to receive newsletters!) when we start releasing the final transcriptions.
One final (yet very important!) note is to thank the project moderators, an incredible team of volunteers who have been our welcome wagon, educators, constructive critics, and power transcribers. Holly, Gerry, and Jo: We could not have done this without you.
If you have any questions about the project or results, please feel free to post on the talk boards — they’re still active and we’d love to hear from you there. Alternatively, please feel free to email contact@zooniverse.org and mention ASM in the email subject line.
 Dr. Samantha Blickhan is the IMLS Postdoctoral Fellow at the Adler Planetarium in Chicago, and the Humanities Lead for Zooniverse. Her current research focuses on crowdsourcing and text, including an examination of individual vs. collaborative transcription methods on the Zooniverse platform.
Dr. Samantha Blickhan is the IMLS Postdoctoral Fellow at the Adler Planetarium in Chicago, and the Humanities Lead for Zooniverse. Her current research focuses on crowdsourcing and text, including an examination of individual vs. collaborative transcription methods on the Zooniverse platform.

Add a comment to: Anti-slavery Manuscripts Final Project Update